
被动信息收集也被成为开源智能。这个阶段不对目标系统进行过多探测,不引起目标系统的发现。只收集目标系统的公开的信息,在被攻击系统看来,我们的行为应该都是正常的。
信息收集通常分为三个阶段:被动信息收集、正常交互、主动信息收集(扫描、探测等)
被动信息收集的内容
-
IP地址段
-
域名信息
-
邮件地址
可以通过邮件地址定位到邮件服务器,可以看是个人搭建的还是公网共开的,主要是为了之后社工的探测使用
-
文档图片数据
有很多公司会把自己公开的信息做成文档、图片、彩页等,这些公开的信息里可能涉及到企业内部的信息,比如有关产品的介绍可以看出公司的性质,地理位置范围等等。我们也很有可能收集到目标公司不想公开的信息,如IT管理文档,就会包括内部网络结构、人员信息等等
-
公司地址
如果知道地址就可以去现场蹲点观察,有可能发现他的无线网络问题或物理渗透的方式,从公司内部进行渗透
-
公司组织架构
可以针对不同部门进行不同的社会工程学的攻击方式,这里的特殊岗位十分重要
-
联系电话
-
人员姓名/职务
-
目标系统使用过的技术架构
通过搜索引擎、一些工具是可以发现一部分的
-
公开的商业信息
比如他最近的合作伙伴,就可以着重从友商的设备下手,友商出现过的网络漏洞就十分重要
信息的用途
- 便于我们在头脑中对目标进行重构
- 便于发现目标的系统架构/主机所在等等
- 便于社会工程学攻击
- 便于进行物理性的渗透
DNS信息收集
一般来说,我们能得到的唯一信息就是目标的域名,其他信息都需要我们再进行收集
DNS的记录种类
- A记录:域名-IP的记录
- C name记录:域名-域名的记录
- NS记录:域名-域名服务器的记录
- MX记录:域名-邮件服务器的记录
- PTR记录:IP-域名的记录
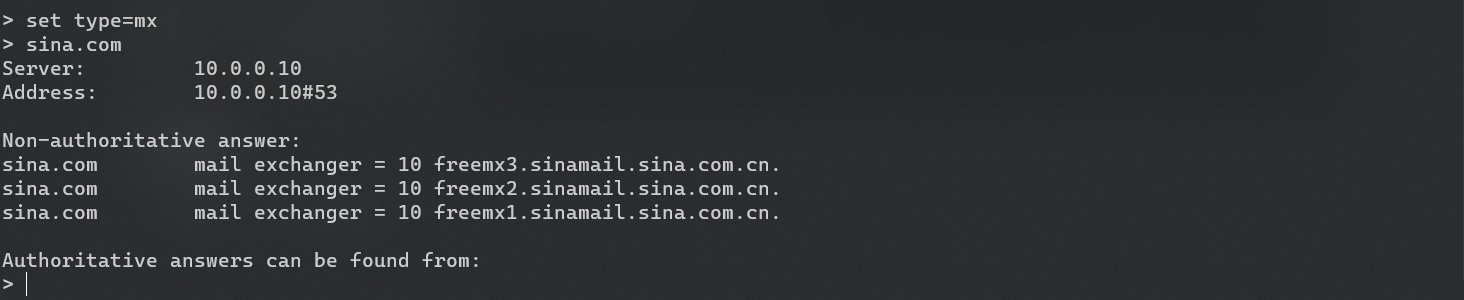
NSLOOKUP
nslookup是一个跨平台的命令,在windows和linux上都可以找到。我们在输入nslookup命令后会首先进入nslookup的命令解释程序,会对我们输入的域名进行逐级映射,这里新浪网址的映射过程就是
www.sina.com -> spool.grid.sinaedge.com. -> 123.126.45.205
这里的server是本地域名服务器

设置type
set type=mx:只查mx记录(也可写作set q=mx)
默认查询类型是a和cname,如果想要查询所有需要设置type为any
这里查到了三条记录,得到了三个邮件交换记录,我们就可以继续用得到的域名往下查。
数字表示优先级,数字越小优先级越高,数字相同的会随机选择。如果当前选用的服务器访问不到,会再尝试使用其他的域名。
设置server
比如把本地域名服务器设置为谷歌的域名服务器:
server 8.8.8.8
不同的本地服务器可能会解析出不同的IP,因为大多数域名都是一个名字对应n个IP,也就是在世界的各地都设有服务器,智能DNS会返回距离源IP最近的服务器的地址,以保证访问的流畅
所以在实际进行信息收集时应多尝试使用不同的本地域名服务器进行查询
命令行使用
后面不跟本地域名服务器则使用本机配置的域名服务器
nslookup -q=any 163.com 114.114.114.114
DIG
功能远远强过nslookup
基本使用方式
dig sina.com any @8.8.8.8
筛选
+noall: 什么都不显示
+answer: 只显示最终查询结果
dig +noall +answer sina.com any @8.8.8.8
反向查询
-x:表示反向查询
dig -x 66.102.251.24
BIND版本查询
大部分linux服务器上的dns解析服务,都是基于bind的软件包进开发的,dig命令可以查询bind版本。如果使用的bind版本存在漏洞,可以攻破dns服务器,就可以从中获取所有的dns记录(所有的子域名)
(然而,本人实践的时候基本都已经connection timed out了,看来时代变了)
dig +noall +answer txt chaos VERSION.BIND @ns3.sina.com
DNS追踪
可以发现域名服务器被劫持的情况
原理:通过跟踪的过程,本地客户端不会向本地域名服务器进行查询,而是直接向根域进行迭代查询。在这个过程中配合抓包会发现地址不正常的现象
dig +trace example.com [@8.8.8.8]
DNS区域传输
对其中同一个域下的一个域名服务器的数据库进行修改之后,DNS服务器之间会使用区域传输的方法来同步数据库,正常情况下,区域传输只发生在本域的域名服务器之间,但如果配置的存在问题,有可能任何人都可以和他进行区域传输,我们就可以获取到该域名服务器所有的主机记录。获取主机记录是DNS信息收集的主要目的
区域传输的传输方法为axfr(request for full zone)
dig @ns1.example.com example.com axfr
也可以使用host命令
这里-T是使用TCP的方式(axfr是使用TCP的53端口),-l是axfr的意思
host -T -l sina.com ns1.sina.com
DNS字典爆破
如果目标DNS服务器没有上述的配置错误,我们可以使用字典爆破的方式来尽可能多的获取主机记录。这里有很多工具可以实现,只要熟练掌握其中一个即可。
字典可以使用工具自带的,也可以使用自己的,字典可以在工具文件夹里搜集(使用find或者dpkg)。推荐把这些工具自带的字典合起来,然后使用其中一个就行
fierce -dnsserver 8.8.8.8 -dns sina.com.cn -wordlist a.txt
# -t指定线程数 -x指定字典的级别[smlxu逐级加强] -d显示ipv6 -4显示ipv4
dnsdict6 -d4 -t 16 -x sina.com
# -o为导出
dnsenum -f dns.txt -dnsserver 8.8.8.8 sina.com -o sina.xml
dnsmap sina.com -w dns.txt
# lifetime为超时时间 -t指定类型 -D指定字典
dnsrecon -d sina.com --lifetime 10 -t brt -D /usr/share/dnsrecon/namelist.txt
dnsrecon -t std -d sina.com
DNS注册信息
除了主机之外,还可以收集一些dns注册的信息,有的域名在注册时候会留下注册人的姓名、电话、邮箱、公司地址等等信息。最好的查询途径就是使用whois,不同地区有不同的whois,因为不同地区的地址分配各自独自:亚太地区、非洲等等。

可以使用各个地区的网页查询,也可以使用whois指令,whois会
whois sina.com
搜索引擎
搜索引擎的作用:
- 公司新闻动态
- 重要雇员信息:比如新雇佣了一个安全研究员等
- 机密文档/网络拓扑
- 用户名密码
- 目标系统软硬件技术架构
- 目标系统历史性的文档等
现在使用搜索引擎进行黑客行为已经成为了一门科学,像谷歌有google hacking、百度的baidu hacking、必应的 bing hacking等。都是有关搜索的一些技术,通过搜索有可能直接搜到目标系统的漏洞,将搜索引擎用熟是黑客的必备技能。
我们需要做的就是将想要的信息从搜索引擎里提取出来
SHODAN
他与google、百度这些搜索引擎是不同的,google、百度是将爬到的网页页面信息存储在自己的数据库里;SHODAN不爬页面,只爬网络上的各种设备,通过http、ftp、ssh等。尤其是现在万物互联,物联网发展迅速,很多物联网设备的安全保护非常脆弱,有相当一部分使用默认账号密码就可以登录。
shodan可以输入写banner信息搜索、也可以使用shodan支持的筛选语句,在/explore中有常见的搜索关键词和方法
常见filter
filter使用:作为定界符,多个参数中间用空格隔开
在搜索到目标IP后,可以显示出这个IP在地图上的位置(现在这个功能要交钱了)
-
net
可以搜索具体IP和网段
net:8.8.8.8 net:61.191.146.0/24 -
country、city
country:CN city:beijing -
port
-
os
-
hostname
hostname:baidu.com -
server
比较好用的搭配
200 OK cisco contry:JP
user:admin pass:password
linux upnp avtech
火狐插件
当访问网页的时候插件会自动查询,可以更为方便的使用

google是综合型的搜索引擎,不同于shodan,不只可以搜索设备,更多的是可以搜索网页等的信息
简单符号
+表示含有 -表示剔除
下面的搜索表示搜索,含有支付但是不含有充值的页面
+支付 -充值
""包含的内容会被作为一个整体来搜索,当搜索较长的文本时尤其是含有空格的文本时是非常方便的
# 搜索含a b的网页
"a b"
# 搜索含a或含b的网页
a b
专用指令
intitle:查找在<title></title>内出现的内容
intext:查找在正文内出现的内容
site:在站点名中搜索,如alibaba.com、cn等等
inurl:搜索在url里存在的关键字,这个指令很常用
filetype:搜索指定类型的文档,pdf、doc等等
eg:
# 北京的电子商务公司的法人的电话
北京 intitle:电子商务 intext:法人 intext:电话
# 阿里网站上的北京公司联系人
北京 site:alibaba.com inurl:contact
# 塞班司法案的pdf文档
SOX filetype:pdf
# 法国的支付页面
payment site:fr
指令使用实例
# 思科交换机用户是分访问级别的,15级是较高的
inurl:"level/15/exec/-/show"
# 这里搜的是一种机架式摄像头的网页,用来监视机房
intitle:"netbotz appliance" "ok"
# url里存在/admin/login.php的页面,就在再找后台管理的登录界面
inurl:/admin/login.php
# 以前网上偷qq密码的,会用木马收集之后上传到某个网页上
inurl:qq.txt
# 含有username或password关键字的xls文件
filetype:xls "username | password"
#
inurl:ftp "password" filetype:"xls" site:baidu.com
# 这是搜frontpage的漏洞,可以直接搜出用frontpage开发的软件的账号密码
# frontpage比较典型,类似的还有很多
inurl:Service.pwd
GHDB(google hacking datebase)
google搜索引擎的搜索语法大全,里面有大量的搜索指令,每一个指令都可以搜到特定性质的一类目标
小知识
Google搜到的页面里会有网址url,旁边有向下的小箭头,点击这个小箭头可以看google爬到页面的时候缓存的信息。因为是爬的html,会丢失掉css样式,但是信息是并不少的。
Yandex——世界第四大搜索引擎
略
kali集成搜索引擎工具
可以并发大量搜索,有时候效率比我们手动更高些
theharvester
通过搜索引擎搜索域下的二级域域名与DNS记录
-d:指定探测的域名
-b:指定搜索引擎或社交媒体
-l:限制搜索结果数量,数量过大会触发搜索引擎的保护机制把我们ban掉,默认每次50
另外,这里可以用tmux终端窗口复用器:可以对shell进行复用
metagoofil
-d:指定域
-t:指定文件类型
-l:限制搜索结果的多少
-n:限制下载的文件数量
-o:指定目录
metagoofil -d microsoft.com -t pdf -l 200 -o test -f 1.html
meltego
很人性化,点鼠标就行。之前学的很多工具都被它集成了起来,而且具有多种视图,由于功能较多但是操作十分简单在,这里就不细说了。
其他
www.archive.org/web/web.php
archive.org会保存一些web网页过去的网址快照,可以了解到目标网站过去的信息和技术。
CUPP(common user password profiler)
这是一个个人专属的密码字典,按个人信息生成他的专属密码字典。
git clone https://github.com/Mebus/cupp.git
python cup.py -i
metadata
无论是相机还是手机,都会在拍摄时记录GPS等信息,很多相机和手机默认开启。
很多摄影爱好者会根据Exif图片信息来调整自己的设备(如光圈等),但是安全工作者更关心设备和GPS的信息
我们可以使用kali中的工具提取exif信息,如exiftool,或者在windows里直接右键属性就能看到
当然这里需要是原图,在网站或软件上经过压缩处理的这很多信息都被抛弃了,我测试了一下我的华为p30的照片还是能够看到经纬度的
RECON-NG
该框架是全特性的web收集框架,基于Python开发,几乎涵盖了所有的被动信息收集的内容,包括DNS、联系人、邮箱等等
命令格式与msf一致
使用
- 按模块使用
- 内置数据库,搜到的结果会以结构化数据的方式自动放入数据库而无需手动记录
- 报告,可以将查询的结构直接按报告生成出来
具体使用
- 输入
recon-ng进入框架命令行,默认进入[recon-ng][defalut](default为默认工作区) help查看使用向导- recon-ng提供很多网站的api接口,但是需要对应的api keys,可以通过
keys来管理apikeys [add / delete / list]keys add x.api yyyyykeys delete x.apikeys list
recon-ng -w指定工作区recon-ng -r指定脚本批量执行命令,脚本存储有recon-ng的一系列命令--no-check使用时不检查升级load装载自定义模块pdb调用python的debugger进行调试query加数据库查询语句对数据库进行查询record对刚才所有执行过的命令进行记录,记录为一个resource文件search搜索相关模块名称set用来设置目标及相关信息等选项的,unset取消设置shell在该框架下执行系统shell命令,shell + 命令showshow options告诉我们当前有哪些选项可以设置show schema显示recon-ng的数据库的结构
snapshots创建当前的工作区快照snapshots [delete/list/load/take]
spool导出资源池use使用各种模块- 使用use可以进入该模块的命令行
- 首先show options,配置options
- 然后run